Cas 1 - Extraction à partir du LiDAR#
L’extraction de la couverture arborée (ou plus justement, d’une couverture de végétation haute) à partir d’un nuage de points 3D LiDAR est une alternative à l’extraction combinant une image NDVI issue d’une Ortho IRC et un MNH. Cet outil suppose que le nuage de points est :
Complet : les fichiers .las couvrant la zone d’étude ont été fusionnés (
Boite à outils QGIS > Gestion de nuage de points > FusionnerClassé : les classes de végétation basse (< 0.5m), moyenne (0.5 m - 1.50 m) et haute (> 1.50 m) sont renseignées dans le nuage de points au format .las
Nous allons extraire la couverture bocagère de la zone d’étude très simplement, en conservant les points de végétation dont la hauteur dépasse un certain seuil (classes de végétation moyenne et haute). Cette façon de faire reste approximative. En effet, elle ne permet pas de contrôler le type de végétation sélectionné. Il peut s’agir de végétation arbustive, arborée et même des cultures qui se trouvent à un stade de croissance avancé (ex. du maïs). Néanmoins, en supposant l’application éventuelle d’un post-traitement par l’utilisateur, cette méthode d’extraction est efficace et très simple d’utilisation. La zone d’étude est celle dans le département de la Manche 50.
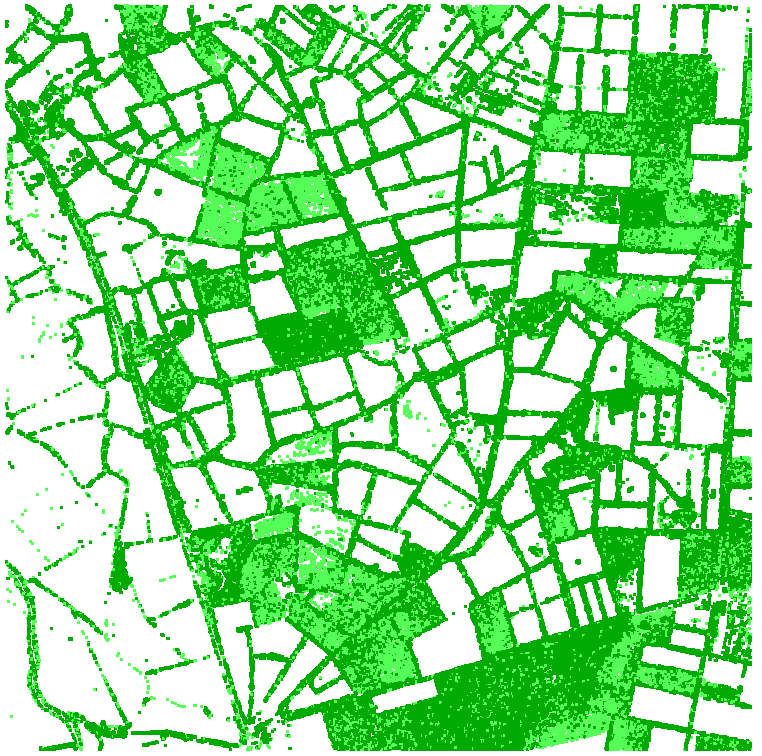
1. Extraction de la couverture de végétation#
Dans le menu de HedgeTools, allez dans
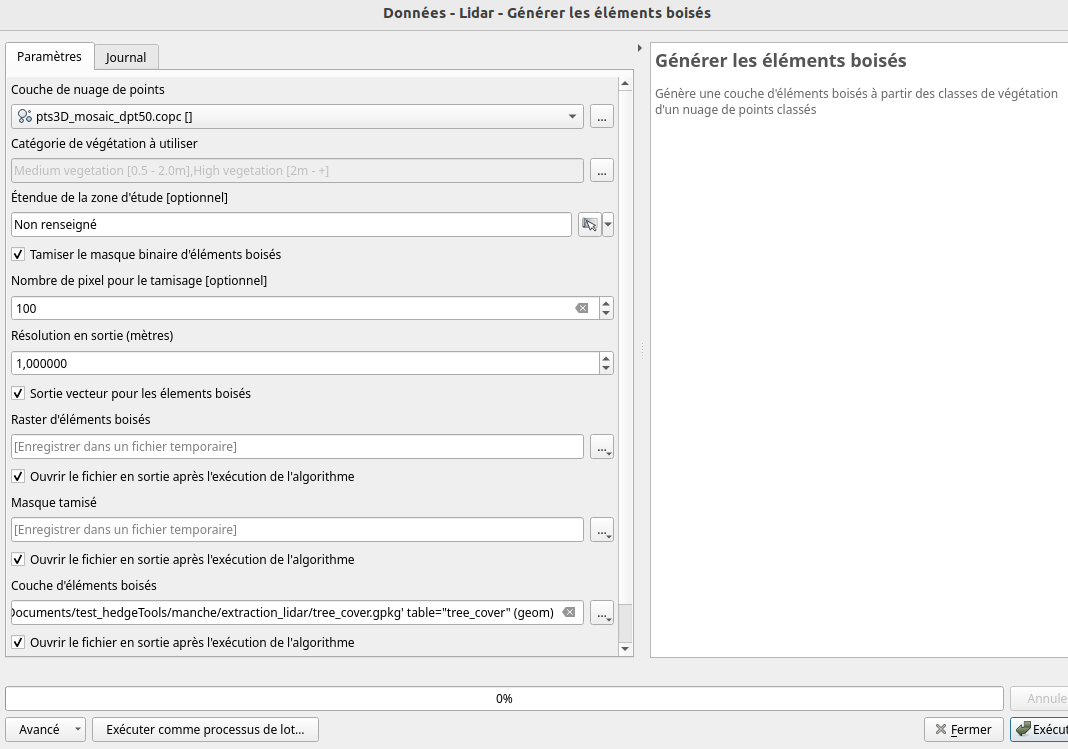
Données - Lidar > Générer les éléments boisésDans la fenêtre de l’outil, renseignez les paramètres avec :
Couche de nuage de points : le fichier ‘pts3D_mosaic_dpt.copc’
Catégorie de végétation : conservez la valeur par défaut qui ne sélectionne pas la végétation basse (<0.5m)
L’étendue de la zone correspond à celle du nuage de points. Il est donc inutile de renseigner ce paramètre optionnel
Conservez la sélection du tamisage (fonction également disponible dans
GDAL > Analyse raster) qui est une opération permettant d’éliminer des groupes de pixels (en sortie) dont la taille en pixels est inférieure à une valeur seuil, définie par le paramètre Nombre de pixels pour le tamisage.Choisissez une résolution spatiale de 1 m pour le raster de sortie
Choisissez un nom pour votre couche vectorielle d’éléments boisés en sortie (ex. ‘tree_cover_MH.gpkg’). Vous pouvez aussi enregistrer une version raster avant et après tamisage.
Le résultat est une couche vectorielle qui contient des polygones obtenus par vectorisation d'un raster de végétation moyenne et haute dérivé du nuage de points LiDAR. La vectorisation est réalisée sur la version du raster *tamisée* (i.e. nettoyée de petits polygones). L'outil génère aussi ces rasters de façon à contrôler le résultat et l'effet du tamisage.
Warning
L’opération de tamisage n’est pas anodine car elle a pour effet d’écarter des petits objets qui sont potentiellement à conserver (ex. un arbre isolé au sein d’une haie lâche). Elle est toutefois nécessaire pour faciliter ensuite la séparation des différents éléments de cette couverture arborée avec l’outil de classification des éléments boisés). Il est donc conseillé de tester plusieurs valeurs de paramètres qui peuvent permettre d’obtenir plusieurs résultats à comparer.
Le résultat est assez convaincant visuellement et laisse penser que les polygones de grande dimension correspondent tous à de la forêt. En réalité, ce n’est pas le cas ! Plusieurs polygones sont des parcelles agricoles puisque nous avons conservé la classe de végétation comprise entre 0.5 et 1.5 m. On peut s’en apercevoir si on superpose la couche générée avec un extrait de la BDOrtho IRC de l’IGN (datant ici de 2022).

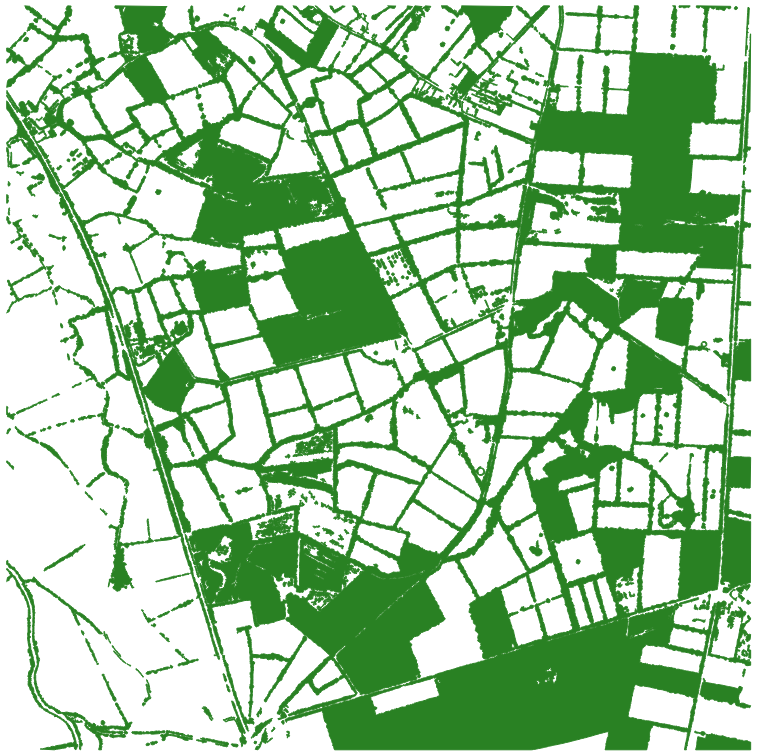
Nous allons produire à nouveau cette couche en ne conservant cette fois que la végétation haute (> 2m), les autres paramètres restent inchangés. La couche de sortie sera nommée ‘tree_cover_H.gpkg’.
Le résultat ci-dessous reste imparfait mais nous éliminerons par la suite si besoin les objets surdétectés par cette méthode (en particulier les parcelles cultivées).

2. Classification de la couverture de végétation#
La couverture de végétation générée précédemment correspond à un agrégat d’objets de différentes natures : des bosquets, des haies, des arbres isolés (et du “bruit”, comme des parcelles cultivées). Nous allons utiliser l’outil de classification pour séparer ces éléments mais au préalable, un pré-traitement doit être opéré pour simplifier la géométrie des objets afin de faciliter cette étape de classification.
Dans le menu de HedgeTools, allez dans
Données - Extraction > Prétraitement CWADans la fenêtre de l’outil, renseignez les paramètres avec :
Couche d’éléments boisés : le fichier de végétation haute (sortie de l’étape précédente)
Seuil de surface (en m2) pour supprimer les petits objets isolés : conservez la valeur par défaut
Tolérance de décalage pour la simplification des géométries : fixez la valeur à 1 m ; ce paramètre est utilisé par l’algorithme de simplification des contours Douglas-Peucker. Nous suggérons de choisir comme valeur la résolution du raster dont la couche de haie est issue de façon à réduire l’effet dentelé des polygones de haies.
Seuil de surface (en m2) pour supprimer les polygones en anneaux : conserver la valeur par défaut
Choisissez un nom pour votre couche vectorielle d’éléments boisés prétraités en sortie : ‘tree_cover_H_preT.gpkg’.
Vous pouvez réappliquer le même traitement sur la couche initiale en appliquant cette fois une valeur de tolérance de décalage pour la simplification des géométries à 0.25 m. Selon la résolution spatiale de votre raster initial, cette valeur peut être trop faible et pourrait n’avoir aucun effet sur la simplification des contours des polygones chargés en entrée.
Nous allons ainsi poursuivre l’exercice avec le fichier ‘tree_cover_H_preT.gpkg’.
Nous allons à présent classer les objets. L’étape de classification qui permet de séparer les haies, des forêts et des autres éléments de la couche de végétation est basée sur une ouverture morphologique (opération d’érosion des objets, suivie d’une dilatation) et d’une analyse des formes résultantes. Elle implique de fixer plusieurs paramètres dont un rayon de zone tampon pour réaliser l’ouverture.
Dans le menu de HedgeTools, allez dans
Données - Extraction > Classification des éléments boisésDans la fenêtre de l’outil, renseignez les paramètres avec :
Couche de polygones : le fichier de végétation précédent prétraité
Taille du tampon (en m) : fixez cette valeur de rayon à 12 m qui signifie approximativement que la largeur maximale des éléments linéaires sera de 24 m.
Valeur seuil pour les forêts (en m2) : conservez la valeur par défaut ; c’est un seuil minimal de superficie ; la définition d’une forêt suppose notamment une surface minimale de 50 ares (5000 m2)
Valeur seuil pour les bosquets (en m2) : conservez la valeur par défaut ; c’est un seuil minimal de superficie ; la définition d’un bosquet suppose une surface comprise entre 5 et 50 ares (500 à 5000 m2)
Choisissez des noms pour les différentes couches vectorielles en sortie (forêt, élément linéaire, bosquet, arbre isolé)
Warning
L’opération de classification peut échouer si le référentiel spatial (CRS) de votre couche n’est pas ou mal défini (ce qui est possible lorsque vous utilisez les rasters de l’Ortho IRC ou du LiDAR). Dans ce cas, il faut donc utiliser l’outil QGIS Assigner une projection pour redéfinir le CRS avant de relancer l’opération.
L’opération de classification peut prendre quelques minutes selon le degré de simplification des contours. Une fois terminé, vous obtenez le résultat ci-dessous :
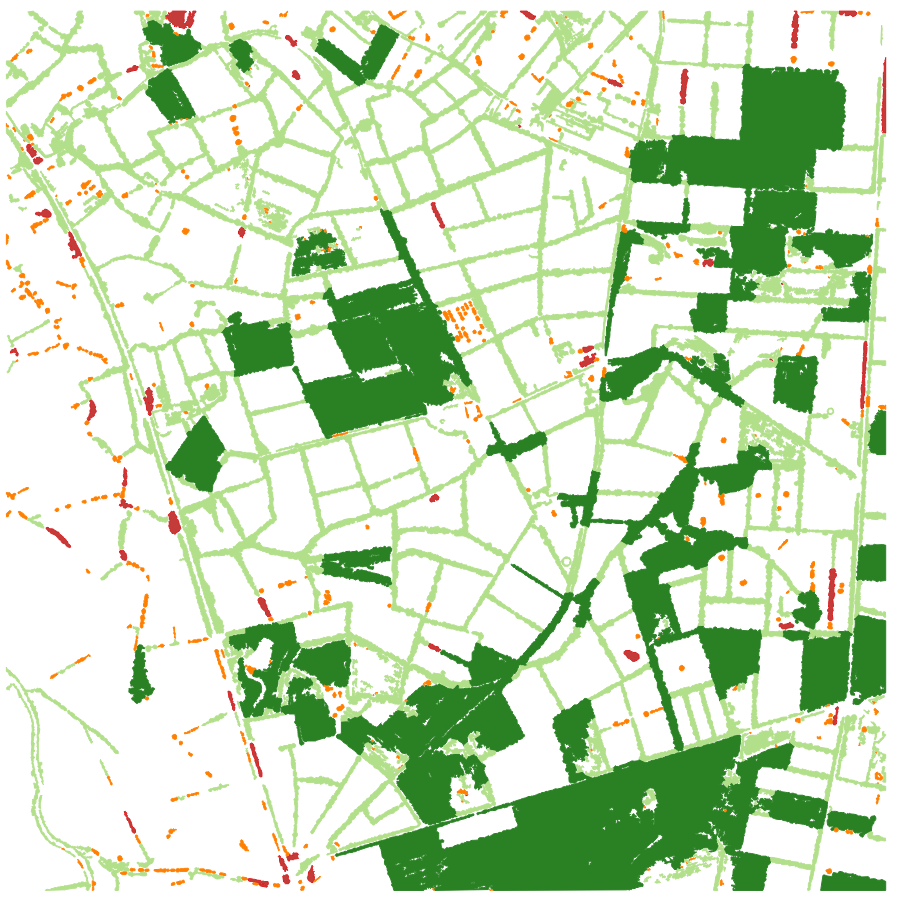
La classification n'est **pas parfaite** avec des défauts de connectivité dans le réseau de haies (c'est une perspective d'amélioration importante de HedgeTools à moyen terme) mais l'outil fournit une première séparation des éléments de végétation qui peut être retouchée manuellement (ou en testant d'autres valeurs de paramètres) au besoin.
Nous poursuivrons le tutoriel avec la couche des éléments linéaires obtenus sans se soucier des imperfections pour l’exercice. Pensez donc à bien enregistrer la sortie relative aux éléments linéaires obtenue lors de cette étape de classification (fichier ‘haies.gpkg’ avec une couche ‘polygones’). L’avantage important de cette couche est que les limites des objets sont précises et en cohérence avec le nuage de points LiDAR. Si ces points 3D sont utilisés par la suite pour caractériser la structure, les métriques ne seront pas biaisées par un écart de position entre les couches.